
仅列表介绍目前(2025年)常见的(指淘宝上可以买到的)一些显卡型号,在对比算力时请注意单位中的”TOPS”和”GOPS“。
文章末尾有常用模型参数量与显存占用的介绍。
Tesla P系列
| 显卡名称 核心 | Tesla P4 GP104 | Tesla P10 GP102 | Tesla P40 GP102 | Tesla P100 GP100 |
|---|---|---|---|---|
| 发布时间 | 2016年9月 | 2016年9月 | 2016年9月 | 2016年6月 |
| GPU 架构 | Pascal | Pascal | Pascal | Pascal |
| 显存大小 | 8GB | 24GB | 24GB | 16 GB |
| 显存类型 | GDDR5 | GDDR5X | GDDR5 | HBM2 |
| 显存位宽 | 256 bit | 384 bit | 384 bit | 4096 bit |
| 显存带宽 | 192.3 GB/s | 694.3 GB/s | 347.1 GB/s | 732.2 GB/s |
| FP64算力 (双精度) | 89.12 GFLOPS | 358.3 GFLOPS | 367.4 GFLOPS | 4.763 TFLOPS |
| FP32算力 (单精度) | 5.704 TFLOPS | 11.47 TFLOPS | 11.76 TFLOPS | 9.526 TFLOPS |
| FP16算力 (半精度) | 89.12 GFLOPS | 179.2 GFLOPS | 183.7 GFLOPS | 19.05 TFLOPS |
| INT8算力 | 22 TOPS | 47 TOPS | ||
| 最大功耗 | 75W | 150 W | 250 W | 250 W |
| 备注 | 有12G显存版 |
Tesla M系列
| 显卡名称 核心 | Tesla M4 GM206 | Tesla M10 GM107 | Tesla M40 GM200 | Tesla M60 GM204 |
|---|---|---|---|---|
| 发布时间 | 2015年11月 | 2016年10月 | 2015年11月 | 2015年8月 |
| GPU 架构 | Maxwell 2.0 | Maxwell | Maxwell 2.0 | Maxwell 2.0 |
| 显存大小 | 4 GB | 8 GB * 4 | 24 GB | 8 GB * 2 |
| 显存类型 | GDDR5 | GDDR5 | GDDR5 | GDDR5 |
| 显存位宽 | 128 bit | 128 bit * 4 | 384 bit | 256 bit * 2 |
| 显存带宽 | 88.00 GB/s | 88.00 GB/s * 4 | 288.4 GB/s | 160.4 GB/s * 2 |
| FP64算力 (双精度) | 68.61 GFLOPS | 52.24 GFLOPS * 4 | 213.5 GFLOPS | 150.8 GFLOPS * 2 |
| FP32算力 (单精度) | 2.195 TFLOPS | 1.672 TFLOPS * 4 | 6.832 TFLOPS | 4.825 TFLOPS * 2 |
| FP16算力 (半精度) | ||||
| INT8算力 | ||||
| 最大功耗 | 50 W | 225 W | 250 W | 300 W |
| 备注 | 有12G显存版 |
M10是在单卡中塞入4个核心,每个核心都带有8G显存,M60则是在单卡中塞入2个核心。虽然这两张卡的面板性能看起来十分优秀,但是实际使用场景十分受限,买了约等于上当受骗。
Tesla 新系列
| 显卡名称 核心 | V100 PCIe 32 GB GV100 | A100 PCIe 80 GB GA100 | H100 PCIe 80 GB GH100 | H100 PCIe 96 GB GH100 |
|---|---|---|---|---|
| 发布时间 | 2018年3月 | 2021年6月 | 2023年3月 | 2023年3月 |
| GPU 架构 | Volta | Ampere | Hopper | Hopper |
| 显存大小 | 32 GB | 80 GB | 80 GB | 96 GB |
| 显存类型 | HBM2 | HBM2e | HBM2e | HBM2e |
| 显存位宽 | 4096 bit | 5120 bit | 5120 bit | 5120 bit |
| 显存带宽 | 897.0 GB/s | 1.94 TB/s | 2.04 TB/s | 3.36 TB/s |
| FP64算力 (双精度) | 7.066 TFLOPS | 9.746 TFLOPS | 25.61 TFLOPS | 31.04 TFLOPS |
| FP32算力 (单精度) | 14.13 TFLOPS | 19.49 TFLOPS | 51.22 TFLOPS | 62.08 TFLOPS |
| FP16算力 (半精度) | 28.26 TFLOPS | 77.97 TFLOPS | 204.9 TFLOPS | 248.3 TFLOPS |
| INT8算力 | ||||
| TF64算力 | 19.49 TFLOPS | |||
| TF32算力 | 155.92 TFLOPs | |||
| BF16算力 | 311.84 TFLOPS | |||
| 最大功耗 | 250 W | 300 W | 350 W | 700 W |
| 备注 | 有16G显存版 | 有40G显存版 |
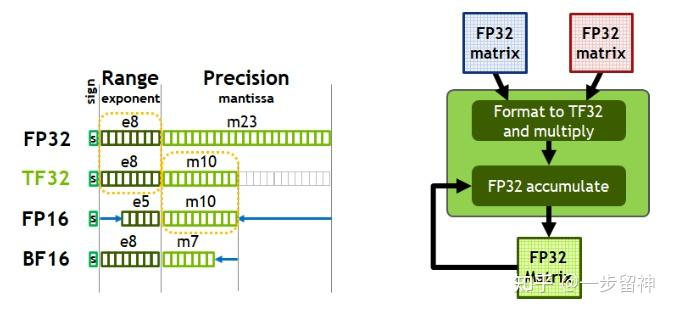
TF32:Tensor Float 32,英伟达针对机器学习设计的一种特殊的数值类型,用于替代FP32。首次在A100 GPU中支持。由1个符号位,8位指数位(对齐FP32)和10位小数位(对齐FP16)组成,实际只有19位。在性能、范围和精度上实现了平衡。
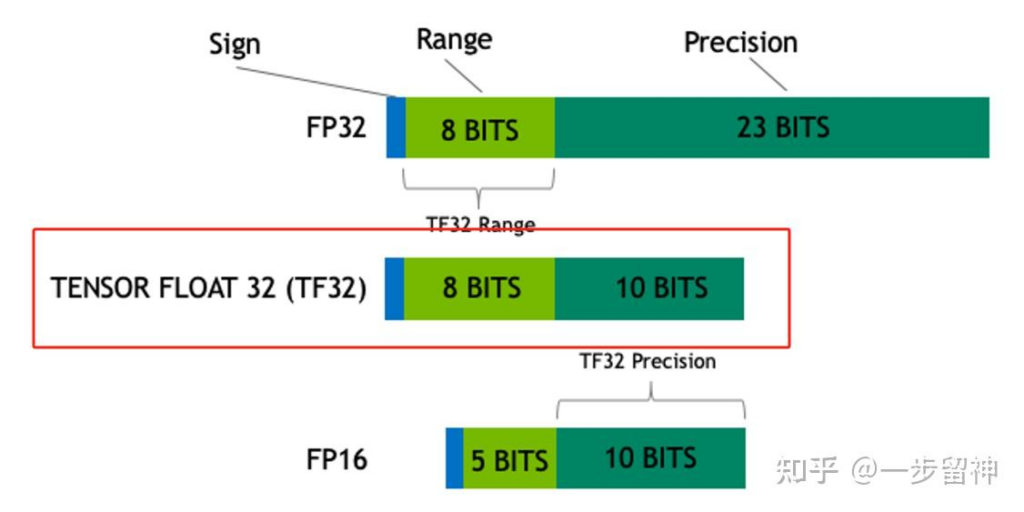
BF16:Brain Float 16,由Google Brain提出,也是为了机器学习而设计。由1个符号位,8位指数位(和FP32一致)和7位小数位(低于FP16)组成。所以精度低于FP16,但是表示范围和FP32一致,和FP32之间很容易转换。
游戏显卡
| 显卡名称 核心 | RTX 5090 GB202 | RTX 4090 AD102 | RTX 5080 GB203 | RTX 4080 AD103 |
|---|---|---|---|---|
| 发布时间 | 2025年1月 | 2022年9月 | 2025年1月 | 2022年9月 |
| GPU 架构 | Blackwell 2.0 | Ada Lovelace | Blackwell 2.0 | Ada Lovelace |
| 显存大小 | 32 GB | 24 GB | 16 GB | 16 GB |
| 显存类型 | GDDR7 | GDDR6X | GDDR7 | GDDR6X |
| 显存位宽 | 512 bit | 384 bit | 256 bit | 256 bit |
| 显存带宽 | 1.79 TB/s | 1.01 TB/s | 960.0 GB/s | 716.8 GB/s |
| FP64算力 (双精度) | 1.637 TFLOPS | 1,290 GFLOPS | 879.3 GFLOPS | 761.5 GFLOPS |
| FP32算力 (单精度) | 104.8 TFLOPS | 82.58 TFLOPS | 56.28 TFLOPS | 48.74 TFLOPS |
| FP16算力 (半精度) | 104.8 TFLOPS | 82.58 TFLOPS | 56.28 TFLOPS | 48.74 TFLOPS |
| INT8算力 | ||||
| 最大功耗 | 575 W | 450 W | 360 W | 320 W |
| 备注 |
移动端显卡
| 显卡名称 核心 | RTX 5090 Mobile GB203 | RTX 4090 Mobile AD103 | RTX 5080 Mobile GB203 | RTX 4080 Mobile AD104 |
|---|---|---|---|---|
| 发布时间 | 2025年1月 | 2023年1月 | 2025年1月 | 2023年1月 |
| GPU 架构 | Blackwell 2.0 | Ada Lovelace | Blackwell 2.0 | Ada Lovelace |
| 显存大小 | 24 GB | 16 GB | 16 GB | 12 GB |
| 显存类型 | GDDR7 | GDDR6 | GDDR7 | GDDR6 |
| 显存位宽 | 256 bit | 256 bit | 256 bit | 192 bit |
| 显存带宽 | 896.0 GB/s | 576.0 GB/s | 896.0 GB/s | 432.0 GB/s |
| FP64算力 (双精度) | 496.9 GFLOPS | 515.3 GFLOPS | 384.0 GFLOPS | 386.3 GFLOPS |
| FP32算力 (单精度) | 31.80 TFLOPS | 32.98 TFLOPS | 24.58 TFLOPS | 24.72 TFLOPS |
| FP16算力 (半精度) | 31.80 TFLOPS | 32.98 TFLOPS | 24.58 TFLOPS | 24.72 TFLOPS |
| INT8算力 | ||||
| 最大功耗 | 95 W | 120 W | 80 W | 110 W |
| 备注 |
顺便解释一下模型参数量和显存之间的关系,在这之前先引入计算机中存储容量转换的概念:
- 1byte(字节)=8bit(比特位)
- 1kb(千字节)=1024byte
- 1mb(兆字节)=1024kb
- 1gb(吉字节)=1024mb
模型参数量通常表示为xxB,例如3B、4B、8B、12B等,这里的B是英文单词十亿(billion)的缩写。也就是说,1B的模型指的是它的参数量为10亿。
假设每个参数占用1bit,那么每8个参数占用为1byte。这样的话1B的模型共占用1,000,000,000/8=125,000,000byte,换算一下约等于0.12GB。
然后模型还有一个量化的概念,指的是每一个参数以什么形式存储。例如FP16量化,指的是将每一个参数读取为float16格式。我们来看一下各个量化参数的具体占用:
- float64
- 别名:fp64/全精度/双精度/Q64
- 每一个参数占用64bit内存,也就是说一个参数占用8byte。
- 如果1B的模型以float64量化,则占用显存为1,000,000,000*8=8,000,000,000byte。
- 8,000,000,000byte=7,812,500KB≈7,629MB≈7.45GB
- 也就是说,1B模型以float64量化载入,将会占用约7.45G显存。
- 这个精度一般只用于模型训练,因为它可以最大限度地保证精度。
- float32
- 别名:FP32/单精度/Q32
- 每一个参数占用32bit内存,也就是说一个参数占用4byte。
- 如果1B的模型以float32量化,则占用显存约3.72GB。
- float16
- 别名:FP16/半精度/Q16
- 每一个参数占用16bit内存,也就是说一个参数占用2byte。
- 如果1B的模型以float16量化,则占用显存约1.86GB。
- 这个精度是推理模型的最佳选择,它可以在保证模型质量损失忽略不计的前提下,最大限度地提升模型推理速度。
- 大部分情况下,人们都是用这个精度加载模型并进行推理。除了那些专门为双精度运算优化的显卡以外,绝大多数显卡的FP16运算性能都是最好的。因此使用该精度量化的模型可以有很好的推理速度。
- INT8
- 别名:Q8
- 每一个参数占用8bit内存,也就是说一个参数占用1byte。
- 如果1B的模型以INT8量化,则占用显存约0.93GB。
- INT8是一个相对比较“穷”的选项,如果你的显存容量无法以FP16精度加载模型,那么试试INT8也是一个不错的选择。只是相较于FP16,INT8量化通常有着较为明显的质量损失。
- 有些模型会对INT8精度进行特别优化,以让它们在INT8精度上同样保持高质量。
- INT4
- 别名:Q4
- 每一个参数占用4bit内存,也就是说一个参数占用0.5byte。
- 如果1B的模型以INT4量化,则占用显存约0.46GB。
- 超级丐版的精度,模型质量损失非常明显。使用INT4量化加载的文本模型有时候会输出一些牛头不对马嘴的上下文。你应该优先考虑参数量更少的模型,而不是将一个大参数量的模型强行以INT4量化加载到你的显存中。
